Starting My Journey In Procedural Generation

The world of procedurally generated data is a fascinating one. It exists in many familiar parts of the computer landscape, from Minecraft to Diablo to Dwarf Fortress. It’s something I’ve been very interested in for quite some time, starting with playing Elite on my Commodore 64 a long long time ago (in a very distant galaxy).
But behind the fun times blowing things up and trying to dock those first few times without an autopilot1, there were questions brewing. How on earth did they manage to get such a large universe into a machine with only 64KB total RAM, let alone render it all? Some dark magic must have been involved, and over time, I became determined to find out which spells were invoked to make it happen. Because I had a plan to make something big…
I’m Just A Lazy Wannabe#
For years, I’ve dabbled in various forms of writing (fun fact - you’re looking at one of them!). My short stories have always revolved around a single small idea, so never needed a huge amount of world-building behind them. Over time, I’ve had one or two ideas for a larger creative endeavour though, and have always been in awe of the worlds created by Tolkien, Jordan and Sanderson. They were always very detailed, with a complex and coherent history, fully fleshed-out geography, and a variety of different cultures. Clearly, a lot of work went into defining these and making them so gorgeously detailed.
I’m a computer guy though. When I hear “that would be a lot of work”, my first instinct is “Can I automate that?” They clearly do a lot of that in Dwarf Fortress for instance, so wouldn’t it be cool to make that generic? Then, I could just press a button and a whole story-ready world would just pop up2! Awesome!
So the idea of randomly generating whole worlds and backstories began fermenting in my brain like a nice strong IPA. At the same time, I began to pay a bit more attention to the rest of the outside world. Train trips, in particular, were very relaxing, but filled with ponderings on “how would I randomly generate what I’m seeing?”. I never had any particularly good ideas at the time, but it was a fun thought exercise, and made me appreciate just how varied the world and its elements could be.
After a long time of thinking about this, this year, I’ve finally decided to try doing something practical, rather than just theorising about the whole thing. So now that we’ve set the scene, how do we actually get started generating something procedurally?
The Deep Black Arts Of Randomness#
There’s a lot of resources out there for sure, but finding the right ones and pulling them together is challenging at best. A bunch of open-source game engines are procedural, but I’m also interested in the theory behind them. Where should I start? There’s one thing that is always required for all types of randomly generated data though, and the key is that first word - randomly.
Random number generators are a really interesting part of computer science. Simulating randomness well is an tricky problem, and there are a bunch of different implementations of pseudo-random number generators out there. A long time ago, I came across two books at Foyles in London3 by Guy W Lecky-Thompson from his Infinite Game Universe series, the first of which was called Mathematical Techniques. The first part of the book goes into detail about random number generators, different generator algorithms, and how seeding fits into it all.
While all this is quite interesting to read about, a lot of analysis on randomness has been done already by people much smarter and (probably!) less grumpy than me. So, given the point above about me being lazy, there’s not a huge amount of value in scientifically proving any of this. It’s not like I’m rolling my own brand new RNG, especially when Rust has a bunch of random number generators ready for use. One interesting takeaway from Guy’s book though was the idea that plotting streams of randomly generated numbers is a quick way to determine how well distributed the output of a RNG is. I thought I’d have a go at doing it myself in Rust, because RIIR.4
There are red and green dots on the scatter graphs below. The red dots plot the random numbers generated for each different call to the RNG. 10,000 samples were taken (the x axis), with a random number being generated between 0 and 10,000 (the y axis). The green line is the important one though. This shows how well distributed the samples are. Each random number is compared to the one generated previously. If the new one is higher, the green line goes up slightly, and if it’s lower, it goes down. If the RNG generates numbers that are well distributed, you’d expect the line to be fairly horizontal, and not too jagged.
I plotted graphs for 4 different RNGs:
- A simple ascending sequence of integers. Not random at all!
- Use the standard RNG from the rand crate.
- The XorShift RNG from the rand_xorshift crate.
- The fantastically named Xoshiro256PlusPlus RNG from the rand_xoshiro crate.
Simple ascending sequence Standard XorShift Xoshiro256PlusPlus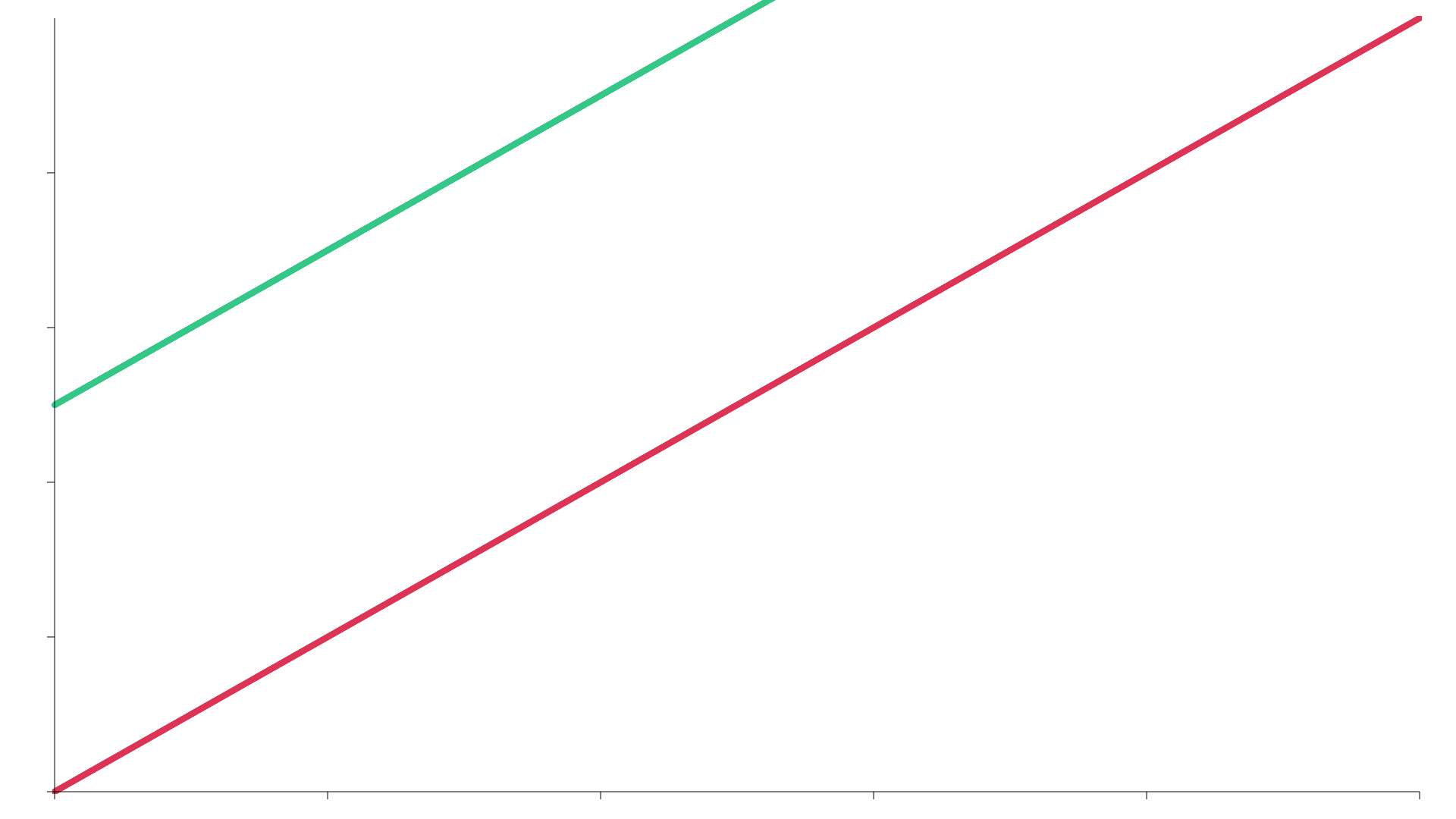
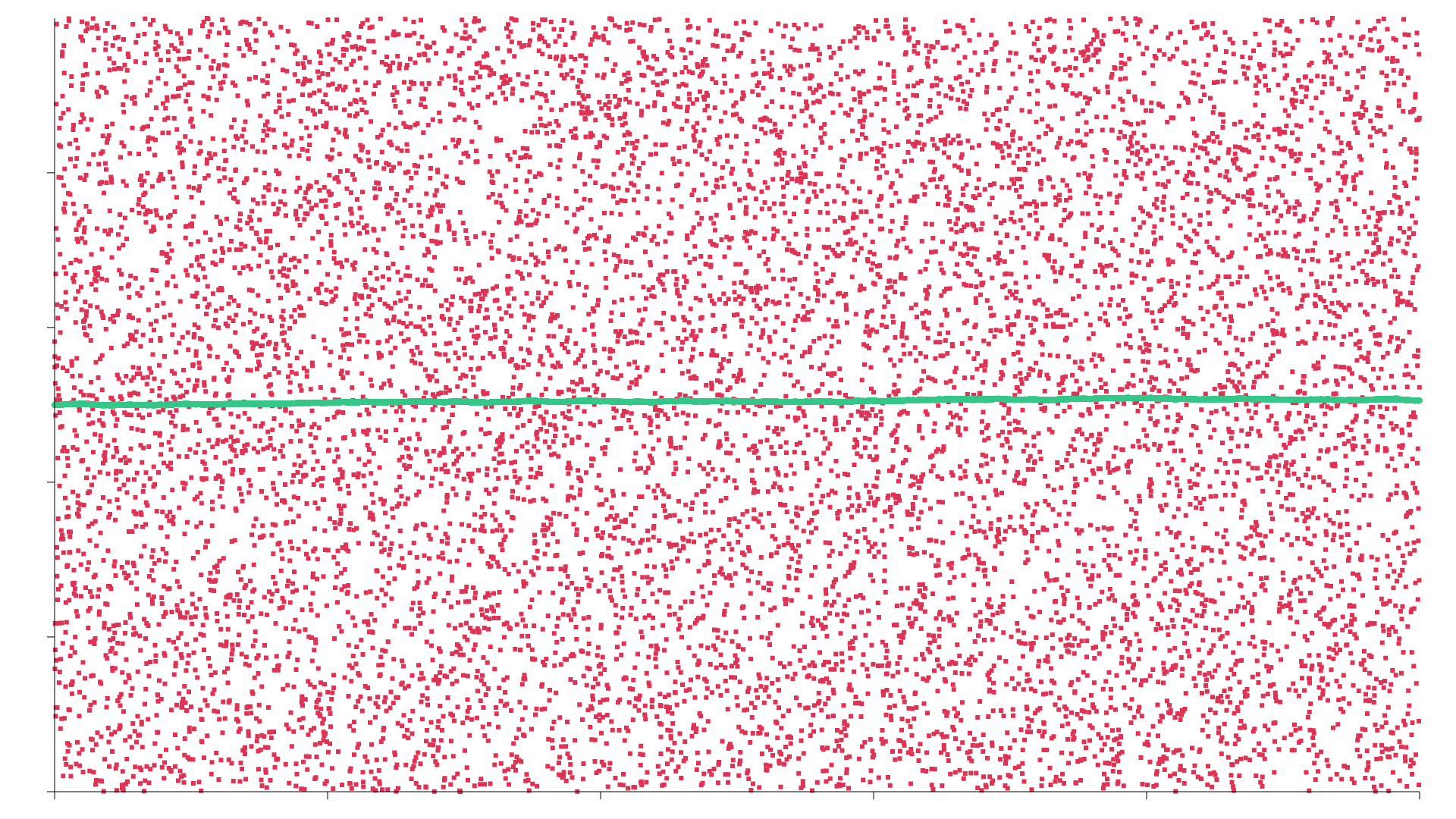
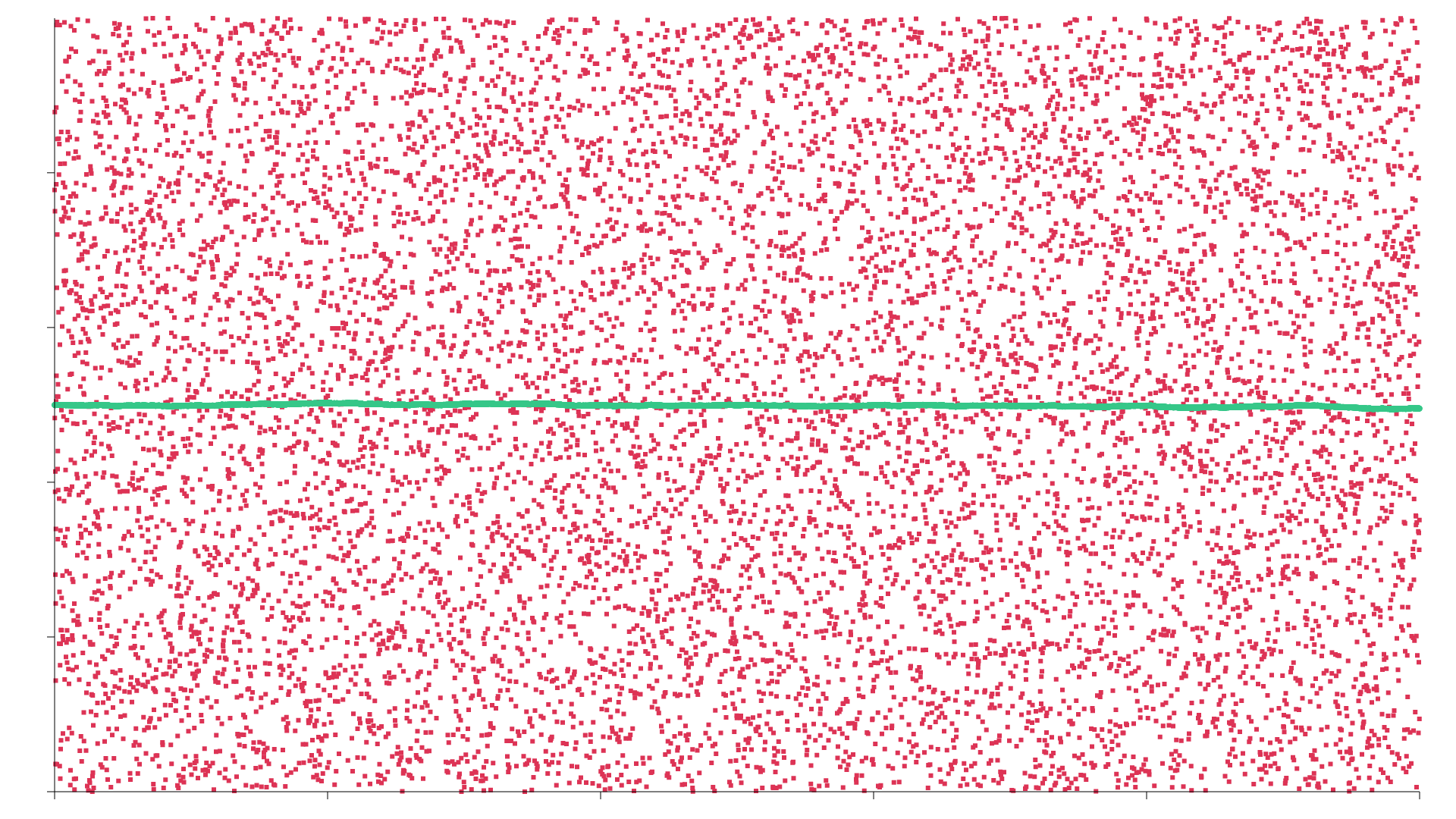

Yeah, you know what, the 3 different real RNGs are all fairly similar, and the sequence is shit, at least for a mere 10,000 samples. To my untrained eye though, the Xoshiro plot is ever so slightly less clumped and the fitness line is slightly less jagged, so for the purposes of playing around, I’m going to declare Xoshiro256PlusPlus the winner.
Spreading Seeds#
Xoshiro and friends are all algorithms, which manipulate their current state to generate a sequence of random numbers. The initial state of a random number generator is called a seed. Each RNG can be created with a default seed that is often just the current clock tick or something derived from it, as this is something that will be different each time the program is run. To allow for reproducibility, a fixed seed can be used, and the stream of random numbers will then be deterministic. All pretty straightforward stuff for the most part.
One very important thing to think about though is what happens when you’re running a simulation that involves both random numbers and multiple processes or threads. This might happen if you have a list of 1 million tasks, and you decide to use a pool of some number of processes to process them in parallel. For each task in your work queue, you will either:
- Start a new process, which will have a different default seed for the RNG.
- Use an existing process, with an effectively random RNG starting state based on how many (and which!) tasks have been processed so far.
Neither of these is particularly useful if you want to be able to debug any of those tasks in more detail, as the behaviour is going to be dependent on the number of processes in the pool and whether you’re restarting the process each time. This might be what you want, for things to be totally random at all times. That doesn’t sit well with me though, as you’ll often need to debug crashes in specific tasks, and that will be difficult in these circumstances. Luckily, there is another way to structure this kind of workload so that you can have randomness per run, but reproducibility for debugging and re-runs.
When you’re creating the different tasks that are going to be distributed for calculation, each task should also be given a random number seed to use when it initialises. The main RNG from the calling code should also have a static seed, and since that process is generating the tasks in a fixed order, the seeds for each task will also be deterministically generated. Super simple in hindsight, but one of those things that you probably wouldn’t have thought of first time around. This will also have the added benefit that you can safely cache partial results from an aborted run if need be, safe in the knowledge that a re-run will have the same output across different runs.
Marching Up The Hill#
The last bit of randomness that we need to have a bit of a clue about is gradient noise. There’s a bit more structure, for want of a better word, to the output of a gradient noise function, which makes it well suited to heightmap-based landscape generation. Perlin noise is the most well known gradient noise function, and works by generating a grid of points, then interpolating between them (using dotproducts or other forms of interpolation). This smooths things out, and it ends up looking something like this (with many thanks to Joni for writing this answer at StackOverflow and generating the following image)

Not the kind of noise I normally write about
If you squint a bit5 and use a hefty dose of imagination, you can almost see the hills and mountains magically springing up from this…
So, now that I’ve drawn some graphs, ruminated on starting conditions, and squinted at some noisy output, it’s time to move onto the next part of the journey - actually generating something procedurally. Onwards and upwards!
-
Put your hand up if you didn’t enable a cheat of some sort or borrow a save game to get one of these before you needed to dock the first time. Yeah, just as I thought. ↩︎
-
Yes, yes, I’m ignoring the fact that in DF, you can read the whole history of everything, but I’m also interested in doing it myself, so there. ↩︎
-
Back when their “computer science” area wasn’t full of “IPads For Dummies”-style books. ↩︎
-
Source code for this can be found at https://github.com/GrumpyMetalGuy/procedural_fitness. It’s not pretty though, I’m rusty at Rust atm. ↩︎
-
Well, quite a lot of squinting is actually required here, but anyway… ↩︎